Practical flow of a Data Science Project
How does a valuable Data Scientist look like?

Have you ever wondered why you, a talented Data Scientist, is not an adviser or a consultant for business, but just a normal employee spending time solving other's requests?
This is such a common complaint that I heard so many times from my friends, my fellows and especially from the junior. Years ago during the beginning of my career, I was also a victim of this trap. Now, I realized that this is a real bottleneck of Data Scientist and I want to share my experience to others so that it will help other Data Scientist achieving a brighter career.
Whenever I meet other Data Science fellows, most of the time was spent talking about RNN, NLP, Deep learning, or Machine learning algorithms. But when I called on a question of why they used RNN instead of Deep learning or how their model supports the business, they could either provide an unconvincing reason or stay on a lengthy explanation of concept, algorithm without a comprehensive business thinking.
It is a routine for a Data Scientist to saturate with technical models while understates the role of business mindset. However, I totally do not deny the integral role of technical work of a data scientist, I only want to emphasize the importance of understanding the business concept at first before any other activities.
Therefore, I list out below a standard flow for starting a data science projects with key points, which I have been applying throughout 4 years working for 2 multinational companies as a data analyst and data scientist. This post was written based on my experience. Hence, take it as your reference and adjust to your own needs.
1. First and foremost importance - Clarifying Business question
During my years in analytics and data science, in addition to technological concept explanation, business question clarification is one of the most difficult tasks when a Data scientist communicates with business partner.
I am sure that you catch this phrase everywhere, in numerous articles, warning you to clarify business question in every situation.
But how?
Working and researching are not identical. In business, top people never stop expecting a Data Scientist to become a wise man who knows the answer for all of their questions. Therefore, digging the problem is our job and how to do that is our responsibility.
It must be very familiar with you when a sales manager asks you “I want to know why sales declined?" or a marketing director demands “How to increase the efficiency of the promotion activity for brand A on our website?"
When you hear these questions, can you imagine the right approach or the answer to the case? Or you will be very vague and keep asking yourself “Is that they want me to do this.” or “I think they want to know that.", and if you deliver the result based on this understanding, how much confidence you have on your result?
In reality, if you keep it this way, the one and only response you will get from them is:
“This is not what I need”
OMG! How terrible it is when you spent so much effort into this, but no one values it.
This is because you did not truly understand problem so that you did not touch the right pain point!
For example, the director wants to know way to improve his marketing activity efficacy, so what does Efficacy mean here? What kind of activity he points to? What are the real pain points? If these concerns are plainly clarified, the request will be interpreted as “How to optimize the budget spending on online promotion in order to increase the purchase rate and new customers vs last year”. This will end up with increasing efficacy.
One of the common advises is to ask “Why” in order to dig into the real problems. However, this solution is not applicable all times because the business partners might not know why for all of your questions.
What can you do more:
-
Ask about the background of the question, why and how they come up with the request after you receive it.
-
Be sure that the request is your responsibility to answer. If your company has several Data teams such as Data Scientist, Data Analyst and BI, make sure to understand the Role & Responsibility of each team and know when to jump in and when to leap out. However, don't ever say “This is not my job. Ask BI”. Instead, show them that you know everything about company and data “With your request, the BI team has already got the data that can help with your question, I suggest you to meet BI and ask for sales and churn rate data of the last 3 years”.
-
Engage with other teams in the company to frequently get updates about other things happened within your company. Moreover, it is extremely important to always raise up questions such as “What are the latest company strategy, calendar, current key projects and recent performance?" or “Do I understand the vision and objectives of the projects that are critical to my company?"
-
Think of initiatives and what you can do more within your expertise to bring the projects to the next level.
Be a thinker, not a doer!
2. Identify the approach for the problem
This part is to place the methodology for the analysis
This step requires a broad knowledge on either statistical models or machine learning approached. In some companies, especially non-tech savvy ones, a data scientist is in charge of both analytics and data science work stream.
With a mixed role of Analytics and Data Science, the approaches for the problem will also diversified with various concepts and models. For example: Linear Regression cannot be used to segment customers or Descriptive analysis cannot predict customer churn.
At first, choosing methodology seems to be effortless but indeed always drives you crazy. If the Sales Director asked Data Science team to forecast the sales for next year based on the amount of budget spending while putting online appearance as company's focus, then which approach/model should be used? If the business wanted the forecast based on the market movement with the outlook of maintaining the current company's leadership position, which approach is correct?
What you can do more:
-
It is fundamental to understand the discrepancy between Descriptive analysis and Predictive analysis (many people are still ambiguous between these 2 concepts). An example of descriptive analysis is the relationship between factors; while prescriptive analysis deals with figuring out the future outcomes of that relationship. Descriptive analysis delivers historical insights and prescriptive analysis foresees future values.
-
Identify the specific type of data to assist the problem approach: The target variable and other variables are continuous, categorical or binary.
-
Understand key problem approaches:
- Binary (2 possible answers) or Multi-class (more than 2 possible answers) classification;
- Regression relationship (relationship between 2 or more factors) or Regression prediction (predict future value using regression model);
- Clustering (cluster unlabeled observation into groups of similar characteristics) or Segmentation (divide observations into specific groups);
- Trend detection (historical movement) or Time-series forecasting (project future value of that movement).
3. Acquire the appropriate data
After identifying the business questions and the approach above, set up data requirement and extract the appropriate data from the data warehouse are the next thing.
Data selection sounds to be straightforward but indeed complicated. To solve the business questions, which kind of data is in need of. For example, is it necessary to have customer's birthday information for the task of predicting churn probability?
Ingest sufficient data will save you tons of effort afterward. Bear in mind the unspoken truth: Garbage in is Garbage out.
Two major problems that usually occur during Data Collection
- The unavailability of data
- The bias of training data
3.1 First, let's look at the unavailability of data
This problem is very common globally in which data is unable to capture at the moment of collection due to the limitation of current digital connection. For instance, it is merely impossible to acquire the time spent in cooking at home.
As a common sense, when the data is nonexistent, you will instantly think of way to get the data. However, you have to consider the consequences of unavailability data including cost, time, resources and if the data is indeed not too important to your model, all the effort you put into it will be down the drain.
Therefore, the solution for this case is to defer inaccessible data and in case the model requires this data for a better result, you will have more resources and confident to invest in obtaining it in the future.
What you can do more if you need more data:
-
Bring along a data request summary when you visit the database owner if you need to talk to other parties for this. The summary form should include background of you project, data requirement, your request. This will help smoothing the discussion and the business partner will give the adequate solution.
-
Change the process/method of collecting data to acquire the right information needed. Work with database owner or IT team or propose to your up-line a system revision plan for approval.
-
Prepare budget and contact an outside data owner if the additional data is vital to improve the model and inaccessible for you.
3.2 Second, the bias of data
This problem is serious especially when the training set gets bias from the beginning, the model will learnt accordingly to that bias and results into an inaccuracy prediction when comparing to the real world.
One of the most famous flaws of bias in data is the Amazon recruiting AI tool that showed bias against women. The tool reviewed candidate's resumes in order to pick the top talents within them. The tool showed an obvious bias against women because its training data is not gender-neutral from the beginning.
Therefore, at first hand, be careful with data and its natural distribution are critical responsibility of every Data Scientist.
What you can do more to eliminate the bias:
-
Ensure the statistical distribution of data and its representatives over population. For example, if the population is made up of 56% of male and 43% of female and 1% of others, the data distribution must be in similar ratio.
-
Verify the split of train, validate and test sets in prediction models to establish a similar allocation of variable and categories.
-
Choose the learning model fitting the problem and reduce the skewness. Some models can reduce the bias in data including clustering or dimension reduction.
-
Monitor the performance in real data. Frequently run statistical test on real data to pick out uncommon case. If the test result shows a statically significant in churn rate among male than female, dig it out. Is it the sudden shift or result of bias?
After getting all the data you need, the next step is thing that a Data scientist usually does:
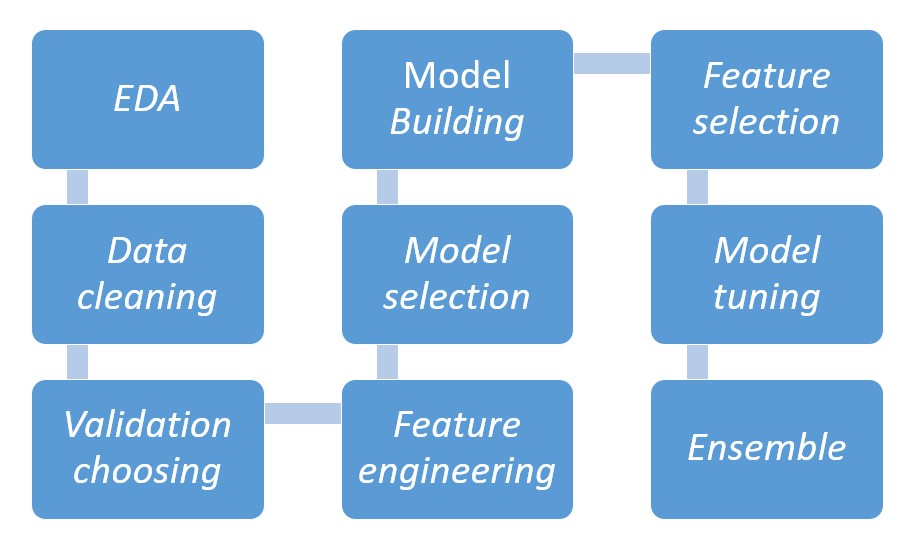
The order can be flexible and this is the standard progress that I usually do in my project and my job. Sometimes, after tuning and the accuracy does not meet my expectation, I need to go back to the feature engineering step to find other way to deal with features.
These are the key bottlenecks beside the technical skills that I want to head up for Data Scientist who want to become more than just a Data insight extractor.
Nhu Hoang
Data Scientist at White Narwhal Japan
Specialized in Recommendation system; Time series; Machine learning and Deep learning. Exploiting is my gut and exploring is my drive.